
คราวก่อนได้เขียนสะท้อนการจัด workshop AI (Artificial Intelligent หรือ ปัญญาประดิษฐ์) ให้กับครูจากหลากหลายสาขา มีทั้งที่มีประสบการณ์มาบ้าง และ มีทั้งที่ไม่มีประสบการณ์เลยอย่างครูปฐมวัย ครูศิลปะ ครูสังคม ครูภาษาไทยก็มี ทำให้รับทราบว่ามีอยู่หลายคนทีเดียวที่คิดว่า “AI คือ หุ่นยนต์” “AI คือ คล้ายๆกับเทคโนโลยีในหนัง Iron Man” “AI คือ สิ่งประดิษฐ์ที่จะมาทำงานแทนคน” (Workshop AI สำหรับครู ณ มูลนิธิศักดิ์พรทรัพย์ ภาพบรรยากาศ และ เนื้อหาบางส่วน ) อันที่จริงผู้เขียนเองก็ไม่ได้จะมาให้คำตัดสินว่าอะไร “ใช่” หรือ “ไม่ใช่” แต่อยากให้ผู้ที่สนใจคำใหม่ๆที่เข้ามาในบริบทยุค Technological Disruption ได้เริ่มมองทุกอย่างแบบที่นักวิทยาศาสตร์มอง คือ สังเกต ตั้งคำถาม/ข้อสันนิษฐาน ตรวจสอบ และสืบค้น แต่การตรวจสอบในบริบทของนักวิทยาศาสตร์ข้อมูลอาจจะไม่ใช่แค่เพื่อสืบค้นหาความจริง (Truth) แต่เป็นการตรวจสอบข้อสันนิษฐานเพื่อนำไปสู่ความรู้ใหม่ (New Knowledge) ในที่นี้อาจตีความได้หลากหลาย เช่น ความเข้าใจในข้อมูลที่ลึกซึ้ง หรือ model ความสัมพันธ์ของข้อมูล เพื่อนำไปใช้ในการสร้าง algorithm ในการตัดสินใจ หรือ เพื่อสื่อสาร
ดังนั้นใน workshop เข้าใจ Data Science and Machine Learning ในแบบ unplugged ที่ได้จัดให้น้องๆ ม. 4 โรงเรียนมอ.วิทยานุสรณ์ จ.สงขลา จึงเน้นที่กระบวนการวิทย์เป็นหัวใจ และก็ย้ำเสมอว่า “Data Science is Science”.
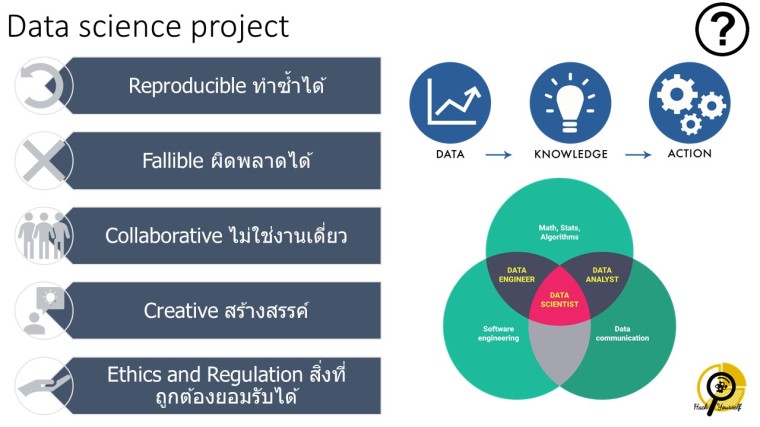
เรายังคงใช้ความสนใจใคร่รู้และกระบวนการตรวจสอบข้อสันนิษฐานในแบบนักวิทยาศาสตร์มาเพื่อหาความรู้ แบบรูป หรือ ความสัมพันธ์ ที่มีความเที่ยงตรงและความเชื่อมั่น เพื่อนำไปสู่กลไกการตัดสินใจที่เป็นระบบ ดังนั้นรูปแบบ data science project จึงต้องประกอบไปด้วยหลายทักษะ ไม่ว่าจะเป็นทักษะการวิเคราะห์ข้อมูลและจัดการข้อมูลด้วยเครื่องมือทางคณิตศาสตร์และสถิติ ทักษะการพัฒนาโปรแกรมในการจัดการข้อมูล ตรวจสอบความเชื่อมั่นและเที่ยงตรง รวมถึงความเข้าใจโครงสร้างของข้อมูล ที่มาของข้อมูล และการสื่อสาร
ด้วยเหตุนี้ Data Science Project จึงมัก
- Reproducible ทำซ้ำได้ — เ่ช่น ข้อมูลชุดใหม่ model เดิม วิธีการเดิม ก็ยังใช้ได้
- Fallible ผิดพลาดได้ — เช่น model เดิม อาจมี bug ที่ต้องแก้ไข เมื่อมีข้อมูลใหม่เพิ่มเข้ามา
- Collaborative ต้องการเพื่อนร่วมงานจากหลายความเชียวชาญ — เช่น ที่มาของข้อมูล เราไม่ได้รู้ไปทุกเรื่อง ถาม domain expert ดีที่สุด
- Creative มีความสร้างสรรค์ — เช่น มองในมุมที่หลากหลาย เพื่อการหา hidden message หรือความสัมพันธ์ที่ซ่อนอยู่
- Ethics and Regulation Accepted มีจริยธรรมและเกณฑ์การทำงานเป็นที่ยอมรับ — การทำงาน การได้มาซึ่งข้อมูล ก็ต้องมีความถูกต้องด้วย
ซึ่งก็ไม่ต่างจาก project ทางวิทยาศาสตร์เลย ที่มีขั้นตอนการทดลองที่ทำซ้ำได้ ที่เราอาจจะเจอความผิดพลาด ที่ต้องแก้ไข และต้องการการร่วมมือจากผู้เชี่ยวชาญด้านอื่นๆ มีการแก้ปัญหาอย่างสร้างสรรค์และถูกต้องตามจริยธรรมในการทดลอง
กล่าวมาถึงตรงนี้ด้วยจุดประสงค์เดียวคือ อยากให้ทุกคนคล้อยตามว่า “Data Science is Science” และมันคงไม่ยากเกินไปสำหรับนักเรียนที่เรียนวิทยาศาสตร์มาทั้งชีวิตอย่างเด็กไทยของเรา
บทความ Hack and Magnify นี้ ผู้เขียนขอออกตัวไว้ก่อนว่าไม่ได้เชียวชาญด้าน AI มากเลย แต่ก็เป็นคนที่ทำงานในสาย data science จริง ในบทบาท Data Analyst จากข้อมูลทางการแพทย์และการตลาด และพยายามสื่อสารสิ่งที่รู้ในสายอาชีพตัวเองให้ออกมาในรูปแบบที่เข้าใจง่ายและสร้างแรงบันดาลความสงสัย ซึ่งอาจนำไปสู่บันดาลใจ ในการเอาข้อมูลที่มีอยู่มาใช้ให้เกิดประโยชน์ และมีการตั้งคำถามวิจัยจากข้อมูลที่มี
Series ของกิจกรรมจึงถูกร้อยมาเป็นเรื่องของ (1) การตั้งคำถามและข้อสันนิษฐานของข้อมูล (2) การเข้าใจกระบวนการ supervised and unsupervised learning และ (3) การใช้ความรู้คณิตศาสตร์จัดการกับข้อมูลที่เราเจอ ดัง 3 กิจกรรมด้านล่างนี้นะคะ (ให้รูปเล่าเรื่องเลยแล้วกันค่ะ)
1. Questioning about the Data
กิจกรรมเริ่มต้นด้วยการให้ข้อมูลในรูปแบบของรูปภาพเรขาคณิต (เหตุผลก็คือ ตีความได้หลากหลาย กระตุ้นความคิดสร้างสรรค์ และการตั้งคำถามให้กับข้อมูลเชิงรูปภาพนี้) โดยในขั้นแรก อยากให้นักเรียนมองและพิจารณาว่าเราตั้งคำถามอะไรได้บ้างจากข้อมูลนี้ (โดยยังไม่มีการกระทำใดๆนอกจากการ มอง -> คิด -> discuss )

เมื่อได้คำถามที่หลากหลาย เราก็เริ่มให้แต่ละกลุ่มได้ตรวจสอบ จากกิจกรรมเห็นนักเรียนหลายกลุ่มเริ่มต้นด้วยการ จับคู่ จัดเรียง จัดประเภท เพื่อตรวจสอบข้อสันนิษฐานที่มี (และเพื่อความง่ายในการ discuss และ การจัดการ เราก็เลยเตรียมรูปมาให้ได้จัดเรียงและจัดการเลย) ซึ่ง unplugged activity นี้ นักเรียนเริ่มได้ sense ของ scientific process และ step เล็กๆ ในการ clean and manage data และ ได้ตั้งคำถามย้อนไปถึงสมมติฐานแรกของกลุ่มว่าจะต้องจัดการอะไรเพิ่มเติมบ้าง 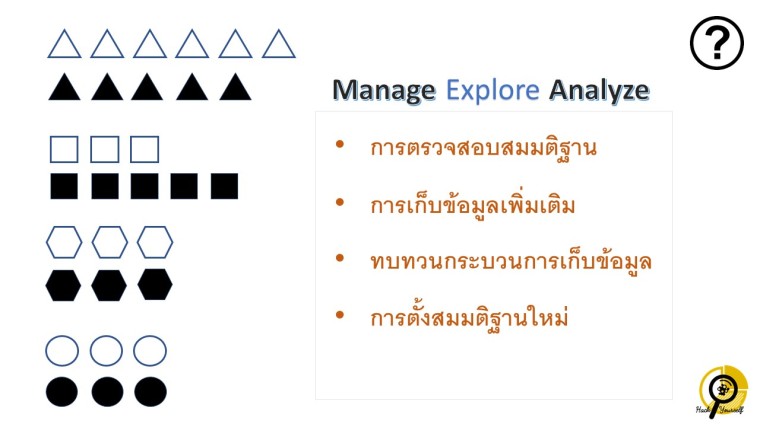
ในวันจัดกิจกรรมมีอาจารย์ที่ร่วมเรียนรู้ไปกับเราและนักเรียนด้วย ท่านชอบกิจกรรมนี้มาก และได้ให้การวิเคราะห์ข้อมูลเชิงลึกมาก โดย ท่านจัดเรียงรูปเรขาคณิต จัดเรียงจำนวนของรูป และ หาความสัมพันธ์กับจำนวนมุมและจำนวนด้าน ออกมาเป็น exponential graph เลยทีเดียว

Key activities ของกิจกรรมนี้คือการตั้งคำถาม หรือ ข้อสันนิษฐานที่มีให้กับข้อมูล การจัดการเพื่อตรวจสอบ และการกลับไปวิเคราะห์ข้อมูลเดิม ว่าการตรวจสอบที่ได้สมเหตุสมผลหรือไม่ เป็นน้ำจิ้มของการทวนกระบวนการวิทย์กับการทดลองในรูปแบบของ data นั่นเอง
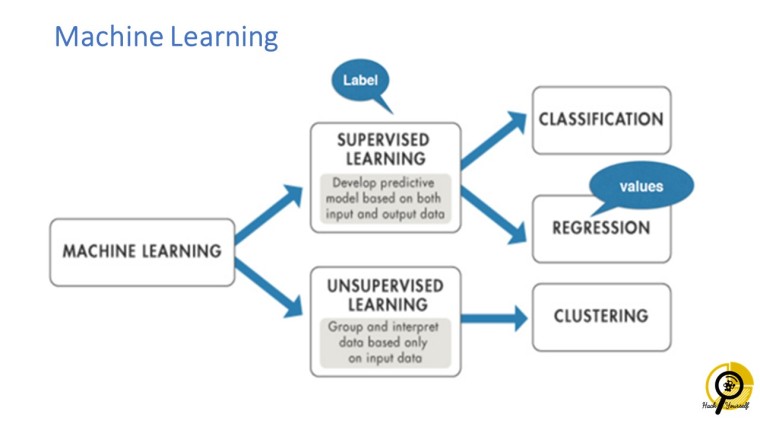
2. Supervised and Unsupervised Machine Learning
ในส่วนนี้เราเพิ่ม lecture เข้ามาประกอบเล็กน้อย ว่าด้วยเรื่องเราสามารถเรียนรู้ได้จากประสบการณ์ เหตุการณ์ที่เจอ machine เอง มันก็เรียนได้จากข้อมูลด้วยวิธีการ assimilation and accommodation เช่นเดียวกัน และก็ให้เด็กๆได้ recall ว่าอันที่จริง เด็กๆก็ใช้ machine learning กันอยู่แล้ว เช่น การทำ linear fit/ linear regression (สำหรับ ม.ปลาย น่าจะได้เรียนแล้ว) และเมื่อมี data point ใหม่เข้ามา (assimilation) เส้น linear fit ก็จะมีการเปลี่ยนแปลง (accommodation) ทำให้ linear fit ทำหน้าที่ได้แม่นยำมากยิ่งขึ้น
แนะนำ regression method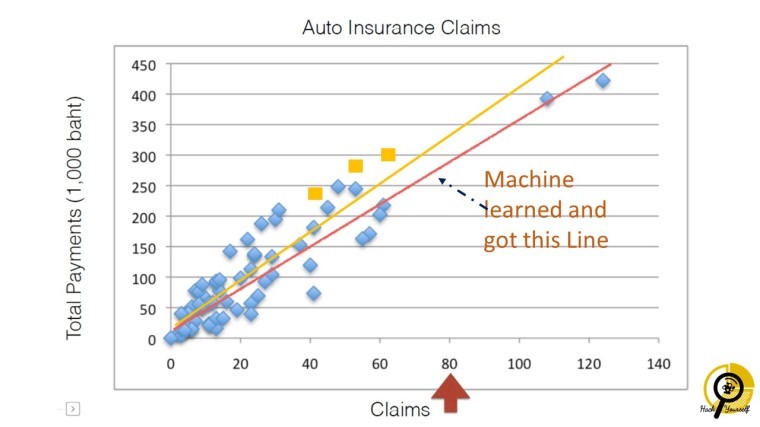
Hands-on Activity #1 – supervised learning
เริ่มต้นจากการเตรียม กล้วย และ แอปเปิ้ลมาให้ classify กัน กิจกรรมนี้นำไปสู่ supervised machine learning หรือ การเรียนรู้แบบมีผู้สอน โดย ข้อมูลตั้งต้นได้สอนให้ machine รับรู้แล้วว่า สิ่งนี้เรียกว่า “กล้วย” สิ่งนี้เรียกว่า “แอปเปิ้ล” เรามาสร้างระบบความคิดให้ machine สามารถ classify ได้ดีกว่า ว่า “แบบไหนถึงจะเป็นกล้วย และ แบบไหนถึงจะเป็นแอปเปิ้ล” เพื่อความง่ายของการเริ่มต้น เราสร้างระบบความคิดนั้นในรูปแบบของแกน x และ แกน y
- นักเรียนระบุแกนเอง และจัดเรียงข้อมูลที่ได้รับการสอนแล้วว่า “เป็นกล้วยนะ” “เป็นแอปเปิ้ลนะ” (เราเรียกข้อมูลกลุ่มนี้ว่า training set) ไปวางในแกน
- ลากเส้น classification หรือ เส้นแบ่งเขตแดนระหว่างกล้วย และ แอปเปิ้ล
- ให้ข้อมูลชุดใหม่ที่เรียกว่า “testing set” คราวนี้จะให้เพื่อนต่างกลุ่มเอาข้อมูล testing set ไปวางในแกนที่เพื่อนทำไว้ โดยทำตัวเป็น machine คือ วางข้อมูลตามตำแหน่งที่แกนระบุ
- เจ้าของกลุ่มตรวจสอบเส้น classification ว่ามีการเปลี่ยนแปลงหรือไม่
- หากมีการเปลี่ยนแปลงเป็นเพราะอะไร ข้อมูลจาก testing set ส่งผลอย่างไร
- และจากกิจกรรมนี้คำว่า machine learn คือ learn อะไร
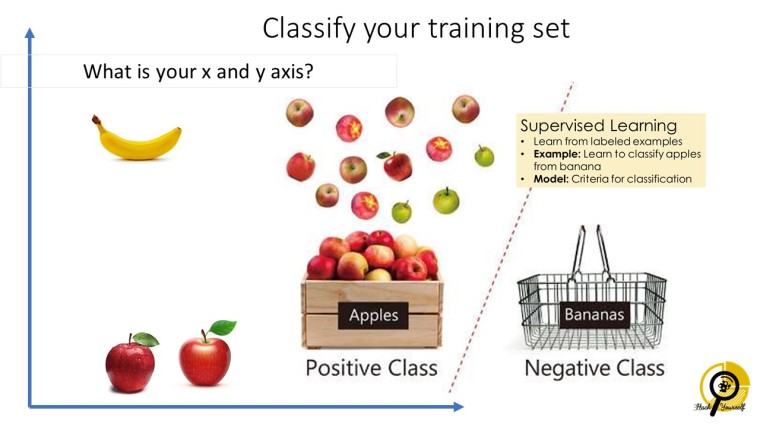
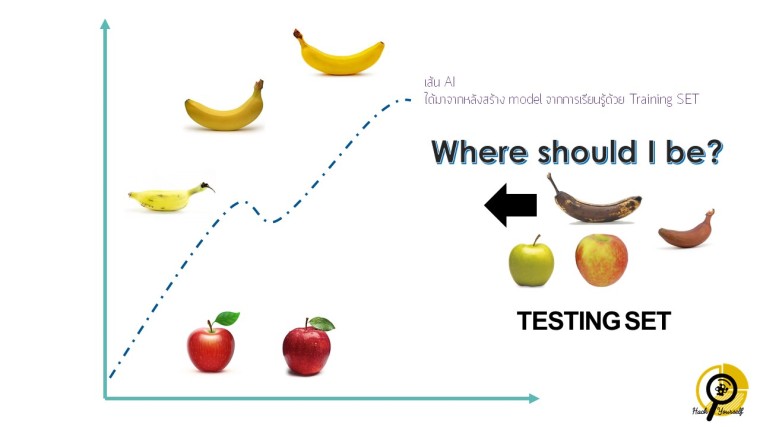
แกน x และ y ก็จะหลากหลายมาก มีทั้งทรงกลม ทรงรี หรือ ละเอียดไปถึงการระบุ RGB ก็มี แค่การคิดแกนของเด็กๆก็น่าสนใจมากทีเดียว
Hands-on Activity #2 – unsupervised learning
กิจกรรม unsupervised machine learning นี ก็ทำต่อเนื่องมา แต่มีการให้รูปผักและผลไม้ที่หลากหลายมากขึ้น และ ให้แต่ละกลุ่มสร้าง criteria ในการจัดเรียง หรือ จัดกลุ่มเอาเอง ในกิจกรรมนี้สิ่งที่เน้นคือ ข้อมูลที่ได้เหล่านี้ยังไม่ถูกสอนมาก่อน ว่า “ฉันคือกะหล่ำ” “ฉันคือฟักทอง” “ฉันคือกล้วย” “ฉันคือแครอท” นักเรียนสามารถสร้างเกณฑ์ในการพิจารณาเอง

บางกลุ่มก็แบ่งได้หลากหลาย แบ่งตามสี และแบ่งย่อยไปเป้นตามขนาด ตามปริมาณ fiber ก็มี และก็มีบางกลุ่มทำออกมาเป็น dendogram เลย คือ เป็นในรุปแบบของ tree-structure น่าสนใจมากทีเดียว
จากนั้นเราก็มาตั้งคำถามกันว่า ถ้าเราอยากให้ machine จัดการข้อมูลให้เราสามารถเลือกผลไม้ไปสกัด เบต้าแคโรทีน (Beta-carotene) machine learning ของกลุ่มใดมีความถูกต้องแม่นยำมากที่สุด และกลับไปถามกลุ่มนั้นว่ามีขั้นตอน หรือ เกณฑ์อะไรในการจัดการข้อมูลให้ออกมาในรุปแบบนี้
(ป.ล. ไม่มีรูปใน activity นี้จริงๆ ด้วยความที่เร่งเวลา ไว้มีจะหามาแปะนะคะ)
3. Words to Vectors, Messages and Relations
มาถึงกิจกรรมใหม่ถอดด้าม ที่เพิ่งจะได้ลองเล่นเป็นครั้งแรก ด้วยจุดประสงค์ที่เราอยากให้ data science and machine learning ใกล้ตัวเข้ามาอีกนิด เราเลยเอา word-to-vector idea มาทำ unplugged activities
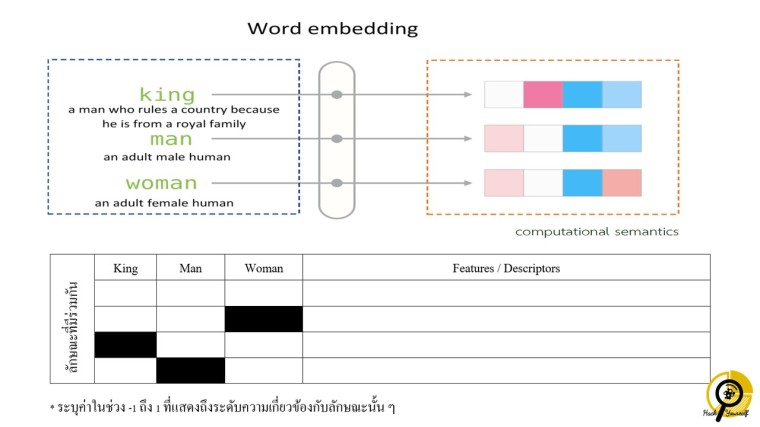

- เริ่มต้นด้วยการ blind arrangement โดยเรามีแถบสีที่ run number ไว้ให้ตรงกับคำศัพท์ที่แทนคนหรือสัตว์ต่างๆ ให้ลองแยกจากค่าของ vector ก่อน (ในที่นี้คือสีและความเข้มของสี) นักเรียนจะไม่รู้เลยว่าแถบสีนั้นแทนอะไร
- ตรวจสอบการจัดกลุ่มหาความสัมพันธ์ของแถบสีกับความหมายจริง เช่น “แถบสีเบอร์ 1 แทน Dog” “แถบสีแบอร์ 3 แทน cat” ซึ่งเราวางจัดกลุ่มให้มีความใกล้เคียงกัน
- สำรวจแถบสีกับคำง่ายๆ เช่น King, Man, Woman, Queen เพื่อเรียนรู้การหาความเหมือนและต่างของคำศัพท์ สกัด feature และใส่ค่าของ vector value ในแต่ละตำแหน่ง feature
- หา similarity value (ซึ่งในการวิเคราะห์จริงทำได้หลายวิธี จะใช้ correlation ก็ได้ แต่เพื่อให้เหมาะกับช่วง ม.ปลาย เราเลยเลือกใช้ dot product) หลังจากนั้นก็ให้แต่ละกลุ่มลองสำรวจความสัมพันธ์ของคำ กับ similarity value อีกครั้ง

กิจกรรมนี้ดูยากทีเดียวในการตีความคำศัพท์เป็น vector format ถ้ามีโอกาสได้ลองอีกจะปรับตัวอย่างใหม่อีกนิดและมีการเชื่อมกับโจทย์จริงๆบ้าง เช่น post ต่างๆ ตาม social media เป็นต้น
สิ่งที่คาดหวังจากกิจกรรมที่ 3 นี้ คือ นักเรียนก็ได้เชื่อมโยงกับการให้ความสัมพันธ์ข้อมูล text ในแบบ Qualitative ที่สามารถจัดการได้ในรูปแบบของ Quantitative data หรือ ในเชิงปริมาณได้ ทำให้เปิดมุมมองในการมองข้อมูลของนักเรียนอีกด้าน ว่าเราเปลี่ยน words เป็น vectors และจัดการกับมันได้ด้วยเครื่องมือทางสถิติและคณิตศาสตร์
พยายามจะเล่าให้เข้าใจแต่ไม่ให้ยาวแล้วนะคะ แต่ก็ยาวจนได้
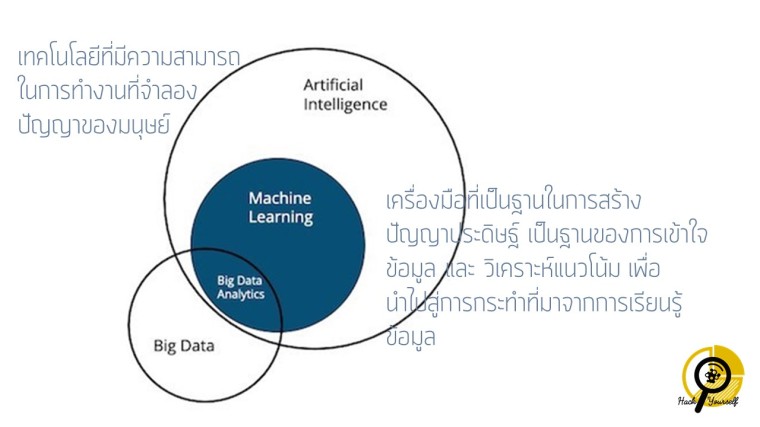
จากกิจกรรมครั้งนี้เราเลือกที่จะปิดท้ายด้วยการที่เรามีมุมมองกับข้อมูลที่หลากหลาย ข้อมูลเชิงปริมาณ และ เชิงคุณภาพ ข้อมูลที่มีรูปแบบที่ไม่แน่นอน มีการเคลื่อนไหวอยู่ตลอด ซึ่งก็เป็นคำตอบว่าทำไมในยุคนี้ถึงเรียกว่ายุค Big Data เพราะ sensor มีอยู่ทุกที่ และเชื่อมโยงกันจนในแต่ละวินาทีมีข้อมูลมากมายถูก generate ออกมาจากทุกๆการกระทำ และ ทุกๆการเคลื่อนไหวของเรา ค่าของข้อมูลเหล่านี้อยู่ที่การที่เราสามารถนำไปใช้เพื่อทำนาย ตัดสินใจในการกระทำในอนาคตที่จะทำให้เราผิดพลาดน้อยลง และมีแนวโน้มที่จะประสบความสำเร็จมากยิ่งขึ้นได้หรือไม่ หรือ เป็นฐานนำไปสู่การกระทำที่มาจากการเรียนรู้ข้อมูล ใช้เป็นกลไกในการสร้างเทคโนโลยีที่มีความสามารถในการทำงานที่จำลองปัญญาของมนุษย์ (AI: Artificial Intelligence) หรือ ปัญญาประดิษฐ์ นั่นเอง
หวังว่าการถอดปลั๊กออกมาจะเป็นประโยชน์กับผู้อ่านทุกท่านนะคะ
Written by SupaDaow
Activities created and implemented by Suparat C. and Artorn N.
